- PKURAL
- Posts
- PDF-GPT: LlamaIndex + Open AI + Pinecone + Fast API
PDF-GPT: LlamaIndex + Open AI + Pinecone + Fast API
Highly optimized content-aware chatbot to query PDF files using embeddings and chat completion APIs of Open AI
Pranav Kural
May 16, 2023

PDF-GPT: LlamaIndex + Open AI + Pinecone + Fast API
Highly optimized content-aware chatbot to query PDF files using Open AI
This article will demonstrate an approach for building highly optimized, cost-effective and content-aware chatbots for querying PDF or text files. We’re going to setup a basic API that will allow us to link a PDF file and ask natural language queries related to the information in the provided document.
For the sake of simplicity, we’re building this project specifically for PDF files, but the model and the architecture described can be used for any other types of documents (basically, anything that can be parsed as textual data).
Let’s dive in 🚀
The Plan 🗺️
What are we trying to achieve? And how will we achieve it?
I like to start with a vision for the end-goal and go backwards, breaking down what needs to be done.
Without adieu, here’s what the API should do when completed:
API Endpoints 🕸️
Using the create endpoint, user provides URL to the PDF file to initiate the creation of a vector store for the data in that file. This vector store will then be stored in Pinecone and will be queried when user makes queries.
/create?document_url={document_url} If an index already created, user can use the load endpoint to initiate the process of loading the existing vector store from Pinecone
/load User can also add more documents or source data by using the update endpoint
/update?document_url={document_url} To make a query and get response, we query endpoint:
/query?q={query text}Primary Tasks 🎯
First part: generate embeddings for the source data and store in vector database
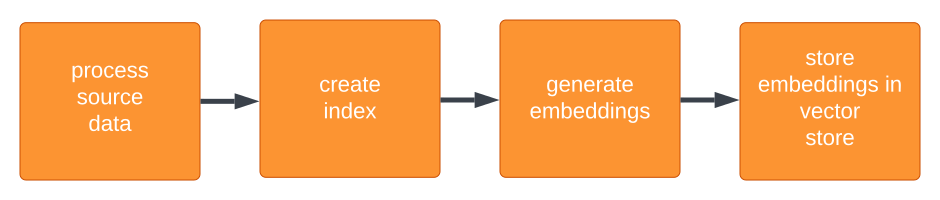
processing source file and creating vector store
Second part: Handling query made by user (once vector store for source data has been created or loaded)

handling user query