- PKURAL
- Posts
- Multimodality powered by Vector Embeddings
Multimodality powered by Vector Embeddings
A quick visual primer on how vectors enable multimodality in machine learning
Pranav Kural
May 29, 2023
Multimodality powered by Vector Embeddings
A quick visual primer on how vectors enable multimodality in machine learning
Let’s see how vector embeddings are used for enabling the training and usage of multimodal machine learning models.
What is multimodal machine learning?
Multimodal ML models and frameworks work with multiple modalities or mediums of data representation like text, image, audio, video, etc.
Such models are capable of connecting the dots between objects of different kinds, or even generate contextually related content of different forms given an object of a certain supported kind. For example, by using a text describing the launch of a rocket into the space as an input to Meta AI’s ImageBind model, we can generate content in five different modalities, i.e., the model will automatically generate an image demonstrating the launch of rocket into space, an audio in the same context, even possibly a video displaying the motion, and more! Learn more here

One True Modality
To perform comparison and to establish some sort of similarity between data of different types, we need a kind of structure to which all these data types can be converted to, so we have a way of deducing similarity or dissimilarity.
There are several ways of representing these bunch of numbers, and one of the most common ones, is representing them as vectors.
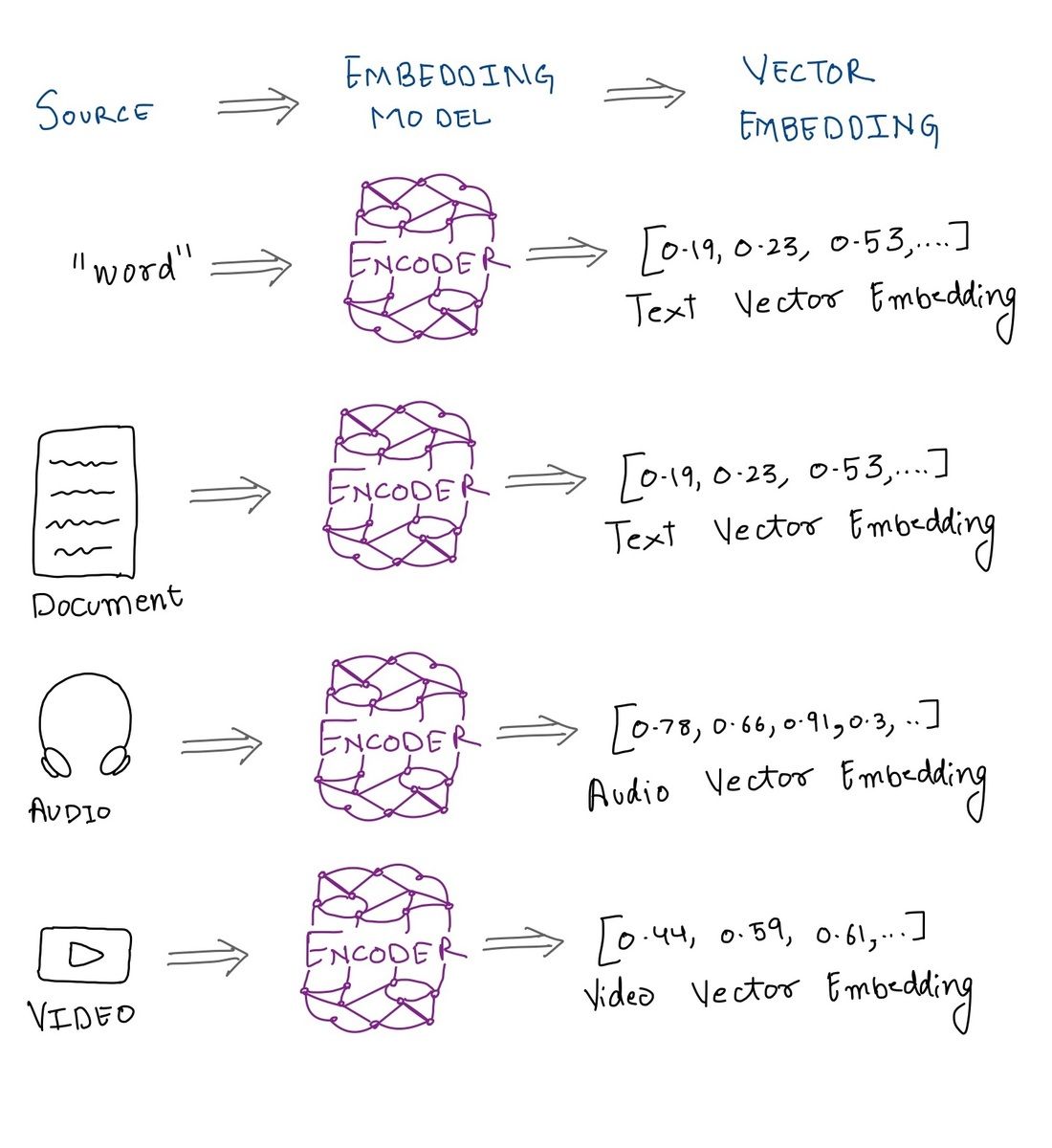
We can use this approach to create models which can generate embeddings for multiple types of data and then use a singular model to establish a relationship between these embeddings.
Distance between two vectors in a vector space help us establish a magnitude of similarity or contrast between two objects. The closer the vector representations of two objects are the more contextually related they are likely to be.
continue reading at pkural.ca